BCA 2ND SEM DBMS NOTES
UNIT 1
BASIC CONCEPTS OF DBMS
Q1 CHARACTERISTICS AND BENEFITS OF A DATABASE?
Self-Describing Nature of a Database System
A Database System contains not only the database itself but also the descriptions of data structure and constraints (meta-data). This information is used by the DBMS software or database users if needed. This separation makes a database system totally different from the traditional file-based system in which the data definition is a part of application programs.
Insulation between Program and Data
In the file based system, the structure of the data files is defined in the application programs so if a user wants to change the structure of a file, all the programs that access that file might need to be changed as well. On the other hand, in the database approach, the data structure is stored in the system catalog not in the programs. Therefore, one change is all that’s needed.
Support multiple views of data
A view is a subset of the database which is defined and dedicated for particular users of the system. Multiple users in the system might have different views of the system. Each view might contain only the data of interest to a user or a group of users.
Sharing of data and Multiuser system
A multiuser database system must allow multiple users access to the database at the same time. As a result, the multiuser DBMS must have concurrency control strategies to ensure several users access to the same data item at the same time, and to do so in a manner that the data will always be correct – data integrity.
Control Data Redundancy
In the Database approach, ideally each data item is stored in only one place in the database. In some cases redundancy still exists so as to improve system performance, but such redundancy is controlled and kept to minimum.
Data Sharing
The integration of the whole data in an organization leads to the ability to produce more information from a given amount of data.
Enforcing Integrity Constraints
DBMSs should provide capabilities to define and enforce certain constraints such as data type, data uniqueness, etc.
Restricting Unauthorised Access
Not all users of the system have the same accessing privileges. DBMSs should provide a security subsystem to create and control the user accounts.
Data Independence
System data (Meta Data) descriptions are separated from the application programs. Changes to the data structure is handled by the DBMS and not embedded in the program.
Transaction Processing
The DBMS must include concurrency control subsystems to ensure that several users trying to update the same data do so in a controlled manner. The results of any updates to the database must maintain consistency and validity.
Providing multiple views of data
A view may be a subset of the database. Various users may have different views of the database itself. Users may not need to be aware of how and where the data they refer to is stored.
Providing backup and recovery facilities
If the computer system fails in the middle of a complex update process, the recovery subsystem is responsible for making sure that the database is restored to the stage it was in before the process started executing.
Managing information
Managing information means taking care of it so that it works for us, and is useful for the work we are doing. The information we collect is no longer subject to “accidental disorganization” and becomes more easily accessible and integrated with the rest of our work. Managing information using a database allows us to become strategic users of the data we have.
Q.2Database Models
Database
systems can be based on different data models or database models respectively.
A data model is a collection of concepts and rules for the description of the
structure of the database. Structure of the database means the data types, the
constraints and the relationships for the description or storage of data
respectively.
The most often used data models are:
|
Network Model and Hierarchical Model |
The network model and the hierarchical model are the predecessors of the relational model. They build upon individual data sets and are able to express hierarchical or network like structures of the real world. |
 Network Model and Hierarchical Model
Network Model and Hierarchical Model
|
Relational Model |
The relational model is the
best known and in today’s DBMS most often implemented database model. It
defines a database as a collection of tables (relations) which contain all
data. |
 Relational Database Model
Relational Database Model
|
Object-oriented Model |
Object-oriented models define a database as a collection of objects with features and methods. A detailed discussion of object-oriented databases follows in an advanced module. |
 Schematic Representation of a Object-oriented Database Model
Schematic Representation of a Object-oriented Database Model
|
Object-relational Model |
Object-oriented models are very powerful but also quite complex. With the relatively new object-relational database model is the wide spread and simple relational database model extended by some basic object-oriented concepts. These allow us to work with the widely know relational database model but also have some advantages of the object-oriented model without its complexity.
|
Q.3Database Architecture
Database architecture is logically divided into two types.
1. Logical two-tier Client / Server architecture
2. Logical three-tier Client / Server architecture
Two-tier Client / Server Architecture

Two-tier Client / Server architecture is used for User Interface program and Application Programs that runs on client side. An interface called ODBC(Open Database Connectivity) provides an API that allow client side program to call the dbms. Most DBMS vendors provide ODBC drivers. A client program may connect to several DBMS's. In this architecture some variation of client is also possible for example in some DBMS's more functionality is transferred to the client including data dictionary, optimization etc. Such clients are called Data server.
Three-tier Client / Server Architecture

Three-tier Client / Server database architecture is commonly used architecture for web applications. Intermediate layer called Application server or Web Server stores the web connectivty software and the business logic(constraints) part of application used to access the right amount of data from the database server. This layer acts like medium for sending partially processed data between the database server and the client.
Q3 SERVICES PROVIDED BY DBMS
i) Data Storage Management: It provides a mechanism for management of permanent storage of the data. The internal schema defines how the data should be stored by the storage management mechanism and the storage manager interfaces with the operating system to access the physical storage.
(ii) Data Manipulation Management: A DBMS furnishes users with the ability to retrieve, update and delete existing data in the database.
(iii) Data Definition Services: The DBMS accepts the data definitions such as external schema, the conceptual schema, the internal schema, and all the associated mappings in source form.
(iv) Data Dictionary/System Catalog Management: The DBMS provides a data dictionary or system catalog function in which descriptions of data items are stored and which is accessible to users.
(v) Database Communication Interfaces: The end-user's requests for database access are transmitted to DBMS in the form of communication messages.
(vi) Authorization / Security Management: The DBMS protects the database against unauthorized access, either international or accidental. It furnishes mechanism to ensure that only authorized users an access the database.
{vii) Backup and Recovery Management: The DBMS provides mechanisms for backing up data periodically and recovering from different types of failures. This prevents the loss of data,
(viii) Concurrency Control Service: Since DBMSs support sharing of data among multiple users, they must provide a mechanism for managing concurrent access to the database. DBMSs ensure that the database kept in consistent state and that integrity of the data is preserved.
(ix) Transaction Management: A transaction is a series of database operations, carried out by a single user or application program, which accesses or changes the contents of the database. Therefore, a DBMS must provide a mechanism to ensure either that all the updates corresponding to a given transaction are made or that none of them is made.
(x) Database Access and Application Programming Interfaces: All DBMS provide interface to enable applications to use DBMS services. They provide data access via Structured Query Language (SQL). The DBMS query language contains two components: (a) a Data Definition Language (DDL) and (b) a Data Manipulation Language (DML).
Q4 Advantages of DBMS
1. Controlling Redundancy: In file system, each application has its own private files, which cannot be shared between multiple applications. 1:his can often lead to considerable redundancy in the stored data, which results in wastage of storage space. By having centralized database most of this can be avoided. It is not possible that all redundancy should be eliminated. Sometimes there are sound business and technical reasons for· maintaining multiple copies of the same data. In a database system, however this redundancy can be controlled.
2. Integrity can be enforced: Integrity of data means that data in database is always accurate, such that incorrect information cannot be stored in database. In order to maintain the integrity of data, some integrity constraints are enforced on the database. A DBMS should provide capabilities for defining and enforcing the constraints.
3. Inconsistency can be avoided : When the same data is duplicated and changes are made at one site, which is not propagated to the other site, it gives rise to inconsistency and the two entries regarding the same data will not agree. At such times the data is said to be inconsistent. So, if the redundancy is removed chances of having inconsistent data is also removed.
Disadvantages of DBMS
The disadvantages of the database approach are summarized as follows:
1. Complexity : The provision of the functionality that is expected of a good DBMS makes the DBMS an extremely complex piece of software. Database designers, developers, database administrators and end-users must understand this functionality to take full advantage of it. Failure to understand the system can lead to bad design decisions, which can have serious consequences for an organization.
2. Size : The complexity and breadth of functionality makes the DBMS an extremely large piece of software, occupying many megabytes of disk space and requiring substantial amounts of memory to run efficiently.
3. Performance: Typically, a File Based system is written for a specific application, such as invoicing. As result, performance is generally very good. However, the DBMS is written to be more general, to cater for many applications rather than just one. The effect is that some applications may not run as fast as they used to.
4. Higher impact of a failure: The centralization of resources increases the vulnerability of the system. Since all users and applications rely on the ~vailabi1ity of the DBMS, the failure of any component can bring operations to a halt.
5. Cost of DBMS: The cost of DBMS varies significantly, depending on the environment and functionality provided. There is also the recurrent annual maintenance cost.
6. Additional Hardware costs: The disk storage requirements for the DBMS and the database may necessitate the purchase of additional storage space. Furthermore, to achieve the required performance it may be necessary to purchase a larger machine, perhaps even a machine dedicated to running the DBMS. The procurement of additional hardware results in further expenditure.
UNIT 2
E-R MODELING
Q.1E-R Diagram
ER-Diagram is a visual representation of data that describes how data is related to each other.

Symbols and Notations

Components of E-R Diagram
The E-R diagram has three main components.
1) Entity
An Entity can be any object, place, person or class. In E-R Diagram, an entity is represented using rectangles. Consider an example of an Organisation. Employee, Manager, Department, Product and many more can be taken as entities from an Organisation.

Weak Entity
Weak entity is an entity that depends on another entity. Weak entity doen't have key attribute of their own. Double rectangle represents weak entity.

2) Attribute
An Attribute describes a property or characterstic of an entity. For example, Name, Age, Address etc can be attributes of a Student. An attribute is represented using eclipse.

Key Attribute
Key attribute represents the main characterstic of an Entity. It is used to represent Primary key. Ellipse with underlying lines represent Key Attribute.

Composite Attribute
An attribute can also have their own attributes. These attributes are known as Composite attribute.

3) Relationship
A Relationship describes relations between entities. Relationship is represented using diamonds.

There are three types of relationship that exist between Entities.
· Binary Relationship
· Recursive Relationship
· Ternary Relationship
Binary Relationship
Binary Relationship means relation between two Entities. This is further divided into three types.
1. One to One : This type of relationship is rarely seen in real world.

The above example describes that one student can enroll only for one course and a course will also have only one Student. This is not what you will usually see in relationship.
2. One to Many : It reflects business rule that one entity is associated with many number of same entity. The example for this relation might sound a little weird, but this menas that one student can enroll to many courses, but one course will have one Student.

The arrows in the diagram describes that one student can enroll for only one course.
3. Many to One : It reflects business rule that many entities can be associated with just one entity. For example, Student enrolls for only one Course but a Course can have many Students.

4. Many to Many :

The above diagram represents that many students can enroll for more than one courses.
Recursive Relationship
When an Entity is related with itself it is known as Recursive Relationship.

Ternary Relationship
Relationship of degree three is called Ternary relationship.
Generalization
Generalization is a bottom-up approach in which two lower level entities combine to form a higher level entity. In generalization, the higher level entity can also combine with other lower level entity to make further higher level entity.

Specialization
Specialization is opposite to Generalization. It is a top-down approach in which one higher level entity can be broken down into two lower level entity. In specialization, some higher level entities may not have lower-level entity sets at all.

Aggregration
Aggregration is a process when relation between two entity is treated as a single entity. Here the relation between Center and Course, is acting as an Entity in relation with Visitor.

UNIT 3
FILE ORGANISATION
Q.1 Hashing
a huge database structure, it can be almost next to impossible to search all the index values through all its level and then reach the destination data block to retrieve the desired data. Hashing is an effective technique to calculate the direct location of a data record on the disk without using index structure.
Hashing uses hash functions with search keys as parameters to generate the address of a data record.
Hash Organization
· Bucket − A hash file stores data in bucket format. Bucket is considered a unit of storage. A bucket typically stores one complete disk block, which in turn can store one or more records.
· Hash Function − A hash function, h, is a mapping function that maps all the set of search-keys K to the address where actual records are placed. It is a function from search keys to bucket addresses.
Static Hashing
In static hashing, when a search-key value is provided, the hash function always computes the same address. For example, if mod-4 hash function is used, then it shall generate only 5 values. The output address shall always be same for that function. The number of buckets provided remains unchanged at all times.

Operation
· Insertion − When a record is required to be entered using static hash, the hash function h computes the bucket address for search key K, where the record will be stored.
Bucket address = h(K)
· Search − When a record needs to be retrieved, the same hash function can be used to retrieve the address of the bucket where the data is stored.
· Delete − This is simply a search followed by a deletion operation.
Bucket Overflow
The condition of bucket-overflow is known as collision. This is a fatal state for any static hash function. In this case, overflow chaining can be used.
· Overflow Chaining − When buckets are full, a new bucket is allocated for the same hash result and is linked after the previous one. This mechanism is called Closed Hashing.

· Linear Probing − When a hash function generates an address at which data is already stored, the next free bucket is allocated to it. This mechanism is called Open Hashing.

Dynamic Hashing
The problem with static hashing is that it does not expand or shrink dynamically as the size of the database grows or shrinks. Dynamic hashing provides a mechanism in which data buckets are added and removed dynamically and on-demand. Dynamic hashing is also known as extended hashing.
Hash function, in dynamic hashing, is made to produce a large number of values and only a few are used initially.

Organization
The prefix of an entire hash value is taken as a hash index. Only a portion of the hash value is used for computing bucket addresses. Every hash index has a depth value to signify how many bits are used for computing a hash function. These bits can address 2n buckets. When all these bits are consumed − that is, when all the buckets are full − then the depth value is increased linearly and twice the buckets are allocated.
Operation
· Querying − Look at the depth value of the hash index and use those bits to compute the bucket address.
· Update − Perform a query as above and update the data.
· Deletion − Perform a query to locate the desired data and delete the same.
· Insertion − Compute the address of the bucket
- If the bucket is already full.
- Add more buckets.
- Add additional bits to the hash value.
- Re-compute the hash function.
- Else
- Add data to the bucket,
- If all the buckets are full, perform the remedies of static hashing.
Hashing is not favorable when the data is organized in some ordering and the queries require a range of data. When data is discrete and random, hash performs the best.
Hashing algorithms have high complexity than indexing. All hash operations are done in constant time.
UNIT 4
RELATIONAL DATA MODEL AND SQL
ACID Properties
A transaction is a very small unit of a program and it may contain several lowlevel tasks. A transaction in a database system must maintain Atomicity,Consistency, Isolation, and Durability − commonly known as ACID properties − in order to ensure accuracy, completeness, and data integrity.
· Atomicity − This property states that a transaction must be treated as an atomic unit, that is, either all of its operations are executed or none. There must be no state in a database where a transaction is left partially completed. States should be defined either before the execution of the transaction or after the execution/abortion/failure of the transaction.
· Consistency − The database must remain in a consistent state after any transaction. No transaction should have any adverse effect on the data residing in the database. If the database was in a consistent state before the execution of a transaction, it must remain consistent after the execution of the transaction as well.
· Durability − The database should be durable enough to hold all its latest updates even if the system fails or restarts. If a transaction updates a chunk of data in a database and commits, then the database will hold the modified data. If a transaction commits but the system fails before the data could be written on to the disk, then that data will be updated once the system springs back into action.
· Isolation − In a database system where more than one transaction are being executed simultaneously and in parallel, the property of isolation states that all the transactions will be carried out and executed as if it is the only transaction in the system. No transaction will affect the existence of any other transaction.
Serializability
When multiple transactions are being executed by the operating system in a multiprogramming environment, there are possibilities that instructions of one transactions are interleaved with some other transaction.
· Schedule − A chronological execution sequence of a transaction is called a schedule. A schedule can have many transactions in it, each comprising of a number of instructions/tasks.
· Serial Schedule − It is a schedule in which transactions are aligned in such a way that one transaction is executed first. When the first transaction completes its cycle, then the next transaction is executed. Transactions are ordered one after the other. This type of schedule is called a serial schedule, as transactions are executed in a serial manner.
In a multi-transaction environment, serial schedules are considered as a benchmark. The execution sequence of an instruction in a transaction cannot be changed, but two transactions can have their instructions executed in a random fashion. This execution does no harm if two transactions are mutually independent and working on different segments of data; but in case these two transactions are working on the same data, then the results may vary. This ever-varying result may bring the database to an inconsistent state.
To resolve this problem, we allow parallel execution of a transaction schedule, if its transactions are either serializable or have some equivalence relation among them.
Q.2 Codd's 12 Rules
Dr Edgar F. Codd, after his extensive research on the Relational Model of database systems, came up with twelve rules of his own, which according to him, a database must obey in order to be regarded as a true relational database.
These rules can be applied on any database system that manages stored data using only its relational capabilities. This is a foundation rule, which acts as a base for all the other rules.
Rule 1: Information Rule
The data stored in a database, may it be user data or metadata, must be a value of some table cell. Everything in a database must be stored in a table format.
Rule 2: Guaranteed Access Rule
Every single data element (value) is guaranteed to be accessible logically with a combination of table-name, primary-key (row value), and attribute-name (column value). No other means, such as pointers, can be used to access data.
Rule 3: Systematic Treatment of NULL Values
The NULL values in a database must be given a systematic and uniform treatment. This is a very important rule because a NULL can be interpreted as one the following − data is missing, data is not known, or data is not applicable.
Q.NEXT
- ER-to-Relational Mapping Algorithm
· STEP 1: For each regular (strong) entity type E in the ER schema, create a relation R that includes all the simple attributes of E. Include only the simple component attributes of a composite attribute. Choose one of the key attributes of E as primary key for R. If the chosen key of E is composite, the set of simple attributes that form it will together form the primary key of R.
Example: From Fig. 3.2
to Fig. 7.5
NOTE: The foreign key and relationship attributes, if
any, are not included yet at this step.
· STEP 2: For each weak entity type W in the ER schema with owner entity type E, create a relation R, and include all simple attributes (or simple components of composite attributes) of W as attributes of R. In addition, include as foreign key attributes of R the primary key attribute(s) of the relation(s) that correspond to the owner entity type(s); this takes care of the identifying relationship type of W. The primary key of R is the combination of the primary key(s) of the owner(s) and the partial key of the weak entity type W, if any.
Example: The DEPENDENT
relation
NOTE: It is common to choose the propagate (CASCADE)
option for the referential triggered action (see Section 8.1) on the foreign
key in the relation corresponding to the weak entity type.
· STEP 3: For each binary 1:1 relationship type R in the ER schema, identify the relations S and T that correspond to the entity types participating in R. Choose one of the relations—S, say—and include as foreign key in S the primary key of T. Include all the simple attributes (or simple components of composite attributes) of the 1:1 relationship type R as attributes of S.
NOTE: It is better to choose an entity type with total
participation in R in the role of S. (WHY?)
Note:When both participations are total, an
alternative mapping of a 1:1 relationship type is possible by merging the two
entity types and the relationship into a single relation. (WHY?)
Example: The MANAGE
relationship
· STEP 4: For each regular binary 1:N relationship type R, identify the relation S that represents the participating entity type at the N-side of the relationship type. Include as foreign key in S the primary key of the relation T that represents the other entity type participating in R. (WHY?)
Examples: WORKS_FOR, CONTROLS, and SUPERVISION
·
STEP
5: For each binary M:N relationship type R, create a new relation S to represent R. Include as foreign key
attributes in S the primary keys of the relations that represent the
participating entity types; their combination will form the primary key of
S.
Note: We cannot represent an M:N relationship type by a single
foreign key attribute in one of the participating relations—as we did for 1:1
or 1:N relationship types . ( Why not?)
Example: WORKS_ON
NOTE: The propagate (CASCADE) option for the referential triggered action (see Section 8.1) should be specified on the foreign keys in the relation corresponding to the relationship R, since each relationship instance has an existence dependency on each of the entities it relates. This can be used for both ON UPDATE and ON DELETE.
· STEP 6: For each multivalued attribute A , create a new relation R. This relation R will include an attribute corresponding to A, plus the primary key attribute K—as a foreign key in R—of the relation that represents the entity type or relationship type that has A as an attribute. The primary key of R is the combination of A and K. If the multivalued attribute is composite, we include its simple components.
Example: a new relation
DEPT_LOCATIONS
NOTE: The propagate
(CASCADE) option for the referential triggered action (see Section 8.1) should
be specified on the foreign key in the relation corresponding to the
multivalued attribute for both ON UPDATE and ON DELETE.
· STEP 7: For each n-ary relationship type R, where n > 2, create a new relation S to represent R. Include as foreign key attributes in S the primary keys of the relations that represent the participating entity types.
Q.3
Characteristics of SQL:
* SQL is an ANSI and ISO standard computer
language
for creating and manipulating databases.
* SQL allows the user to create, update, delete, and
retrieve data from a database.
*SQL is very simple and easy to learn.
*SQL works with database programs like DB2, Oracle,
MS Access, Sybase, MS SQL Sever etc.
Advantages of SQL:
* High Speed:
SQL Queries can be used to retrieve large amounts of
records from a database quickly and efficiently.
* Well Defined Standards Exist:
SQL databases use long-established standard,
which is being adopted by ANSI & ISO. Non-SQL
databases do not adhere to any clear standard.
* No Coding Required:
Using standard SQL it is easier to manage database
systems without having to write substantial amount
of code.
* Emergence of ORDBMS:
Previously SQL databases were synonymous with
relational database. With the emergence of Object
Oriented DBMS, object storage capabilities are
extended to relational databases.
Disadvantages of SQL:
* Difficulty in Interfacing:
Interfacing an SQL database is more complex than
adding a few lines of code.
* More Features Implemented in Proprietary way:
Although SQL databases conform to ANSI & ISO
standards, some databases go for proprietary
extensions to standard SQL to ensure vendor lock-in
Q.4
HASH COLLISION RESOLUTION TECHNIQUES:
Open Hashing (Separate chaining)
Open
Hashing, is a technique in which the data is not directly stored at the hash
key index (k) of the Hash table. Rather the data at the key index (k) in
the hash table is a pointer to the head of the data structure where the data is
actually stored. In the most simple and common implementations the data
structure adopted for storing the element is a linked-list.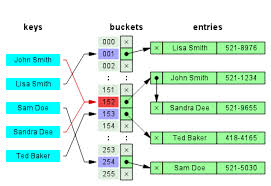
In this technique when a data needs to be searched, it might become necessary (worst case) to traverse all the nodes in the linked list to retrieve the data.
Note that the order in which the data is stored in each of these linked lists (or other data structures) is completely based on implementation requirements. Some of the popular criteria are insertion order, frequency of access etc.
Q.5
normalization definition
In creating a database, normalization is the process of organizing it into tables in such a way that the results of using the database are always unambiguous and as intended. Normalization may have the effect of duplicating data within the database and often results in the creation of additional tables. (While normalization tends to increase the duplication of data, it does not introduce redundancy, which is unnecessary duplication.) Normalization is typically a refinement process after the initial exercise of identifying the data objects that should be in the database, identifying their relationships, and defining the tables required and the columns within each table.
First normal form (1NF). This is the "basic" level of normalization and generally corresponds to the definition of any database, namely:
· It contains two-dimensional tables with rows and columns.
· Each column corresponds to a sub-object or an attribute of the object represented by the entire table.
· Each row represents a unique instance of that sub-object or attribute and must be different in some way from any other row (that is, no duplicate rows are possible).
· All entries in any column must be of the same kind. For example, in the column labeled "Customer," only customer names or numbers are permitted.
Second normal form (2NF). At this level of normalization, each column in a table that is not a determiner of the contents of another column must itself be a function of the other columns in the table. For example, in a table with three columns containing customer ID, product sold, and price of the product when sold, the price would be a function of the customer ID (entitled to a discount) and the specific product.
Third normal form (3NF). At the second normal form, modifications are still possible because a change to one row in a table may affect data that refers to this information from another table. For example, using the customer table just cited, removing a row describing a customer purchase (because of a return perhaps) will also remove the fact that the product has a certain price. In the third normal form, these tables would be divided into two tables so that product pricing would be tracked separately.
Two-Phase Locking 2PL
This locking protocol divides the execution phase of a transaction into three parts. In the first part, when the transaction starts executing, it seeks permission for the locks it requires. The second part is where the transaction acquires all the locks. As soon as the transaction releases its first lock, the third phase starts. In this phase, the transaction cannot demand any new locks; it only releases the acquired locks.

Two-phase locking has two phases, one is growing, where all the locks are being acquired by the transaction; and the second phase is shrinking, where the locks held by the transaction are being released.
To claim an exclusive (write) lock, a transaction must first acquire a shared (read) lock and then upgrade it to an exclusive lock.
Q.6
DBMS - Deadlock
In a multi-process system, deadlock is an unwanted situation that arises in a shared resource environment, where a process indefinitely waits for a resource that is held by another process.
For example, assume a set of transactions {T0, T1, T2, ...,Tn}. T0 needs a resource X to complete its task. Resource X is held by T1, and T1 is waiting for a resource Y, which is held by T2. T2 is waiting for resource Z, which is held by T0. Thus, all the processes wait for each other to release resources. In this situation, none of the processes can finish their task. This situation is known as a deadlock.
Deadlocks are not healthy for a system. In case a system is stuck in a deadlock, the transactions involved in the deadlock are either rolled back or restarted.
What are the Deadlock handling techniques in database?
A set of transactions are considered to be in a deadlock state, if the transactions are waiting for one another to release the data items needed for them that are held by others. In a deadlock state no transaction will proceed.
The deadlock
can be handled by rolling back a transaction which would be chosen as the
victim.
Deadlock can be handled in the following ways;
Deadlock Prevention – this concept ensures that the system never enters a deadlock state. It chooses the transaction which would probably cause the deadlock and rolls-back the transaction.
Deadlock
Detection – this
identifies the deadlock if any happened and recovers the system from deadlock.
Deadlock
Recovery - recovers the system from deadlock state. It chooses the identified transaction
which caused the deadlock, and rolls-back it.
PRACTICAL
INTRODUCTION TO SQL
Pronounced as SEQUEL: Structured QUERY Language
SQL is a language to operate databases; it includes database creation, deletion, fetching rows, modifying rows, etc. SQL is an ANSI (American National Standards Institute) standard language, but there are many different versions of the SQL language.
What is SQL?
SQL is Structured Query Language, which is a computer language for storing, manipulating and retrieving data stored in a relational database.
SQL is the standard language for Relational Database System. All the Relational Database Management Systems (RDMS) like MySQL, MS Access, Oracle, Sybase, Informix, Postgres and SQL Server use SQL as their standard database language.
Also, they are using different dialects, such as −
Ø MS SQL Server using T-SQL,
Ø Oracle using PL/SQL,
Ø MS Access version of SQL is called JET SQL (native format) etc.
Why SQL?
SQL is widely popular because it offers the following advantages −
Ø Allows users to access data in the relational database management systems.
Ø Allows users to describe the data.
Ø Allows users to define the data in a database and manipulate that data.
Ø Allows to embed within other languages using SQL modules, libraries & pre- compilers.
Ø Allows users to create and drop databases and tables.
Ø Allows users to create view, stored procedure, functions in a database.
Ø Allows users to set permissions on tables, procedures and views.

Types of SQL Commands
Ø SQL commands are instructions. It is used to communicate with the database. It is also used to perform specific tasks, functions, and queries of data.
Ø SQL can perform various tasks like create a table, add data to tables, drop the table, modify the table, set permission for users.
There are five types of SQL commands: DDL, DML, DQL , DCL, and TCL.
1. Data Definition Language (DDL)
2. Data Manipulation Language (DML)
3. Data Query Language (DQL)
4. Data Control Language (DCL)
5. Transaction Control Language (TCL)
DDL - Data Definition Language
Data Definitin Language helps you to define the database structure or schema.
DDL or Data Definition Language actually consists of the SQL commands that can be used to define the database schema. It simply deals with descriptions of the database schema and is used to create and modify the structure of database objects in the database.
Ø DDL changes the structure of the table like creating a table, deleting a table, altering a table, etc.
Ø All the command of DDL are auto-committed that means it permanently save all the changes in the database.
Here are some commands that come under DDL:
Types of DDL commands
1. CREATE
2. ALTER
3. DROP
1.

![]() CREATE
:- CREATE statements is used to
define the database structure schema and to create TABLE. used to create the database
or its objects (like table,
index, function, views,
store procedure and triggers).
CREATE
:- CREATE statements is used to
define the database structure schema and to create TABLE. used to create the database
or its objects (like table,
index, function, views,
store procedure and triggers).
![Text Box: Syntax:- CREATE TABLE TA LE_NAME (COLUMN_NAME DATATYPES[,….]);](file:///C:\Users\DEEPAK\AppData\Local\Temp\msohtmlclip1\01\clip_image012.gif) |
B
Example:- Create table employee(e_id int ,ename
char(10),eaddress char(20),salary int );
|
B |
Output :-
2.
 DROP :- Drops commands
remove tables and database from RDMBMS and used to delete objects
from the database.
DROP :- Drops commands
remove tables and database from RDMBMS and used to delete objects
from the database.
 |
Example:- Drop table employee ;
Output :-
3. ALTER:- ALTERS command allows
you to alter the structure of the database.
ALTER:- ALTERS command allows
you to alter the structure of the database.
 |
Example:- Alter table employee ADD father name char(10);
Output :-

 ALTER
ALTER
 |
M
Example:- alter
table employee modify ename char(20);
|
M |
Output :-
 |
|
 ALTER
ALTER
 |
Example:- alter table employee drop column esalary;
Output :-
 |
DML - Data Manipulation Language
Data Manipulation Language allows you to modify the database instance by inserting, modifying and deleting its data.
The SQL commands that deals with the manipulation of data present in the database belong to DML or Data Manipulation Language and this includes most of the SQL statements
.
Ø DML commands are used to modify the database. It is responsible for all form of changes in the database.
Ø The command of DML is not auto-committed that means it can't permanently save all the changes in the database. They can be rollback.
Ø
Here are some commands that come under DML:
Types of DML commands
1. INSERT
2. UPDATE
3. DELETE
1.
|
 INSERT:- This is a
statement is a SQL query. This command is used to insertdata into the row of a table.
INSERT:- This is a
statement is a SQL query. This command is used to insertdata into the row of a table.
 |
Example:- INSERT INTO employee values

Output :-
(107,’gaurav’,’sikandra’,30000);
2.  UPDATE :- This command is used to update or modify the value of a column
in the table.
UPDATE :- This command is used to update or modify the value of a column
in the table.
 |
Example:- Update employee set E_id=101 where E_id=100;
Output :-
3.  DELETE :- This command
is used to remove one or more rows from a table .
DELETE :- This command
is used to remove one or more rows from a table .
 |
Example:- DELETE FROM employee WHERE E_id=102;
Output :-
DQL - Data Query Language
Data Query Language is used to fetch the data from the database . It uses only one command.
DML statements are used for performing queries on the data within schema objects. The purpose of DQL Command is to get some schema relation based on the query passed to it.
SELECT Clause: Here one has to list the columns in a table(s) to display as a result of the query. columns can be from the list of tables mentioned in FROM clause. A from clause can have a sub query instead of a physical table or view. we will cover this in detail, don't get lost. We can also use Oracle functions or custom functions to return single value return functions.
Equivalent to the projection operation in relational algebra, SELECT command selects the attribute based on the condition described by the WHERE clause.
DQL is used to fetch the data from the database. It uses only one command:
Ø SELECT
|
helps you to select the attribute based on the

![]() Condition described by the WHERE clause.
Condition described by the WHERE clause.
 |
|
Output :-
 FOR ANY ONE
COLUMN & MULTI COLUMN
FOR ANY ONE
COLUMN & MULTI COLUMN
 |
Example:- select E_id,Ename from employee;
Output :-
FOR ANY SPECIAL OR INDIVIDUAL DATA
 |
|
|
Output :-
DCL - Data Control Language
Data Control Language includes commands like GRANT and REVOKE, which are useful to give “rights and permissions”. Other permission controls parameters of the database system.
Types of DCL commands
1.GRANT:- This command is use to give user access privileges to a database.
![Text Box: Syntax:- GRANT privilege_name ON object_name TO
{user_name[public] role_name} [with grant option]](file:///C:\Users\DEEPAK\AppData\Local\Temp\msohtmlclip1\01\clip_image059.gif) |
2.REVOKE:- It is useful to back permission from the user.
![Text Box: Syntax:- REVOKE privilege_name ON object_name FROM
{user_name[PUBLIC]role_name}](file:///C:\Users\DEEPAK\AppData\Local\Temp\msohtmlclip1\01\clip_image060.gif) |
TCL
- Transaction Control
Language
TCL commands can only use with DML commands like INSERT, DELETE and UPDATE only.
These operations are automatically committed in the database that's why they cannot be used while creating tables or dropping them.
Here are some commands that come under TCL:
Types of TCL commands
1. COMMIT
2. ROLLBACK
3. SAVEPOINT
Transactin Control Language or TCL commands deal with the transaction within the database.
1. COMMIT :- This command is used
to save all the transactins to the database .
 |
Example:- commit;
Output:-
 |
2.  ROLLBACK :- This command allows you to undo transactions that have not already been saved to the database.
ROLLBACK :- This command allows you to undo transactions that have not already been saved to the database.
 |
Example:- Rollback;
Outout:-
3.  SAVEPOINT :- This command helps you to set within
a transaction.
SAVEPOINT :- This command helps you to set within
a transaction.
Example:- savepoint kain1;
savepoint kain2;
a savepoint

Outout:-
PRACTICAL FILE
MANORAMA INSTITUTE OF MANAGEMENT & TECHNOLOGY.
Ladamda, Fatehpur Sikri Road, Agra, Uttarpradesh.
BCA 2ND Semester
DBMS File
 |
SESSION 2023-24
Submitted By: Submitted To: Mr.
DECLARATION
I hereby declare that the project work submitted to
Mr. …………………. , Manoram Institute Of Management & Technology Is prepared by me.
All the file work and coding are result of my personal efforts.
STD.NAME
BCA 2ND semester
Signature

ACKNOWLEDGMENT
I would like to express my special thanks of my teacher
Mr. ……………….. who gave me the golden opportunity to do this Wonderful Assignment , which also helped me in doing a lot of research And I came
to know about so many new things . I am really thankful to them
Secondly I would also like to thank my parents and friends who helped me a lot in finalizing this assignment within the limited time frame.
STD. NAME
BCA 2ND semester
CERTIFICATE
This is to certify that Mr. …………….of class BCA 2ND semester of Manorama Institute Of Management & Technology , Agra, has completed this project under my supervision. He has taken interest and shown utmost sincerity
of completion of this project. He been successfully completed “
Project Work in DATA BASE MANAGEMENT SYSTEM (DBMS)”
up to my satisfaction.
Date: Mr. Teacher Name
Signature
INDEX OF FILE
|
Sr.No. |
Topic |
Page No. |
|
1 |
Introduction to SQL |
1 |
|
2 |
Types of SQL Commands |
2 |
|
3 |
DDL Commands |
3 |
|
4 |
CREATE |
4 |
|
5 |
DROP |
5 |
|
6 |
ALTER |
6-8 |
|
7 |
DML Commands |
9 |
|
8 |
INSERT |
10 |
|
9 |
UPDATE |
11 |
|
10 |
DELETE |
12 |
|
11 |
DQL Commands |
13 |
|
12 |
SELECT |
14-15 |
|
13 |
DCL Commands |
16 |
|
14 |
GRANT |
16 |
|
15 |
REVOKE |
16 |
|
16 |
TCL Commands |
17 |
|
17 |
COMMIT |
18 |
|
18 |
ROLLBACK |
19 |
|
19 |
SAVEPOINT |
20 |
INTRODUCTION TO SQL
Pronounced as SEQUEL: Structured QUERY Language
SQL is a language to operate databases; it includes database creation, deletion, fetching rows, modifying rows, etc. SQL is an ANSI (American National Standards Institute) standard language, but there are many different versions of the SQL language.
What is SQL?
SQL is Structured Query Language, which is a computer language for storing, manipulating and retrieving data stored in a relational database.
SQL is the standard language for Relational Database System. All the Relational Database Management Systems (RDMS) like MySQL, MS Access, Oracle, Sybase, Informix, Postgres and SQL Server use SQL as their standard database language.
Also, they are using different dialects, such as −
Ø MS SQL Server using T-SQL,
Ø Oracle using PL/SQL,
Ø MS Access version of SQL is called JET SQL (native format) etc.
Why SQL?
SQL is widely popular because it offers the following advantages −
Ø Allows users to access data in the relational database management systems.
Ø Allows users to describe the data.
Ø Allows users to define the data in a database and manipulate that data.
Ø Allows to embed within other languages using SQL modules, libraries & pre- compilers.
Ø Allows users to create and drop databases and tables.
Ø Allows users to create view, stored procedure, functions in a database.
Ø Allows users to set permissions on tables, procedures and views.
Types of SQL Commands
Ø SQL commands are instructions. It is used to communicate with the database. It is also used to perform specific tasks, functions, and queries of data.
Ø SQL can perform various tasks like create a table, add data to tables, drop the table, modify the table, set permission for users.
There are five types of SQL commands: DDL, DML, DQL , DCL, and TCL.
1. Data Definition Language (DDL)
2. Data Manipulation Language (DML)
3. Data Query Language (DQL)
4. Data Control Language (DCL)
5. Transaction Control Language (TCL)
DDL - Data Definition Language
Data Definitin Language helps you to define the database structure or schema.
DDL or Data Definition Language actually consists of the SQL commands that can be used to define the database schema. It simply deals with descriptions of the database schema and is used to create and modify the structure of database objects in the database.
Ø DDL changes the structure of the table like creating a table, deleting a table, altering a table, etc.
Ø All the command of DDL are auto-committed that means it permanently save all the changes in the database.
Here are some commands that come under DDL:
Types of DDL commands
1. CREATE
2. ALTER
3. DROP
1.
![]() CREATE
:- CREATE statements is used to
define the database structure schema and to create TABLE. used to create the database
or its objects (like table,
index, function, views,
store procedure and triggers).
CREATE
:- CREATE statements is used to
define the database structure schema and to create TABLE. used to create the database
or its objects (like table,
index, function, views,
store procedure and triggers).
![Text Box: Syntax:- CREATE TABLE TA LE_NAME (COLUMN_NAME DATATYPES[,….]);](file:///C:\Users\DEEPAK\AppData\Local\Temp\msohtmlclip1\01\clip_image019.gif) |
B
Example:- Create table employee(e_id int ,ename
char(10),eaddress char(20),salary int );
|
B |
Output :-
2.DROP :- Drops commands
remove tables and database from RDMBMS and used to delete objects
from the database.
|
Example:- Drop table employee ;
Output :-
3.ALTER:- ALTERS command allows
you to alter the structure of the database.
|
Example:- Alter table employee ADD father name char(10);
Output :-
 ALTER
ALTER
|
M
Example:- alter
table employee modify ename char(20);
|
M |
Output :-
 |
|
 ALTER
ALTER
|
Example:- alter table employee drop column esalary;
Output :-
 |
DML - Data Manipulation Language
Data Manipulation Language allows you to modify the database instance by inserting, modifying and deleting its data.
The SQL commands that deals with the manipulation of data present in the database belong to DML or Data Manipulation Language and this includes most of the SQL statements
.
Ø DML commands are used to modify the database. It is responsible for all form of changes in the database.
Ø The command of DML is not auto-committed that means it can't permanently save all the changes in the database. They can be rollback.
Ø
Here are some commands that come under DML:
Types of DML commands
1. INSERT
2. UPDATE
3. DELETE
1.
|
 INSERT:- This is a
statement is a SQL query. This command is used to insertdata into the row of a table.
INSERT:- This is a
statement is a SQL query. This command is used to insertdata into the row of a table.
|
Example:- INSERT INTO employee values

Output :-
(107,’gaurav’,’sikandra’,30000);
2.  UPDATE :- This command is used to update or modify the value of a column
in the table.
UPDATE :- This command is used to update or modify the value of a column
in the table.
 |
Example:- Update employee set E_id=101 where E_id=100;
Output :-
3.  DELETE :- This command
is used to remove one or more rows from a table .
DELETE :- This command
is used to remove one or more rows from a table .
 |
Example:- DELETE FROM employee WHERE E_id=102;
Output :-
DQL - Data Query Language
Data Query Language is used to fetch the data from the database . It uses only one command.
DML statements are used for performing queries on the data within schema objects. The purpose of DQL Command is to get some schema relation based on the query passed to it.
SELECT Clause: Here one has to list the columns in a table(s) to display as a result of the query. columns can be from the list of tables mentioned in FROM clause. A from clause can have a sub query instead of a physical table or view. we will cover this in detail, don't get lost. We can also use Oracle functions or custom functions to return single value return functions.
Equivalent to the projection operation in relational algebra, SELECT command selects the attribute based on the condition described by the WHERE clause.
DQL is used to fetch the data from the database. It uses only one command:
Ø SELECT
|
helps you to select the attribute based on the
![]() Condition described by the WHERE clause.
Condition described by the WHERE clause.
|
|
Output :-
FOR ANY ONE
COLUMN & MULTI COLUMN
 |
Example:- select E_id,Ename from employee;
Output :-
FOR ANY SPECIAL OR INDIVIDUAL DATA
|
|
|
Output :-
DCL - Data Control Language
Data Control Language includes commands like GRANT and REVOKE, which are useful to give “rights and permissions”. Other permission controls parameters of the database system.
Types of DCL commands
1.GRANT:- This command is use to give user access privileges to a database.
|
2.REVOKE:- It is useful to back permission from the user.
|
TCL
- Transaction Control
Language
TCL commands can only use with DML commands like INSERT, DELETE and UPDATE only.
These operations are automatically committed in the database that's why they cannot be used while creating tables or dropping them.
Here are some commands that come under TCL:
Types of TCL commands
1. COMMIT
2. ROLLBACK
3. SAVEPOINT
Transactin Control Language or TCL commands deal with the transaction within the database.
1. COMMIT :- This command is used
to save all the transactins to the database .
 |
Example:- commit;
Output:-
 |
2.  ROLLBACK :- This command allows you to undo transactions that have not already been saved to the database.
ROLLBACK :- This command allows you to undo transactions that have not already been saved to the database.
 |
Example:- Rollback;
Outout:-
3.  SAVEPOINT :- This command helps you to set within
a transaction.
SAVEPOINT :- This command helps you to set within
a transaction.
Example:- savepoint kain1;
savepoint kain2;
a savepoint



Comments
Post a Comment